
Here we go again for a new post 😁 After publishing my Quarkus book last September, I got many requests about creating reactive applications with the Quarkus Framework.
Today, I will show you how to make a Reactive CRUD Application with the Quarkus Framework and backed by a PostgreSQL Database.
Building our the Reactive Quarkus Application
The full source code is available on my Github.
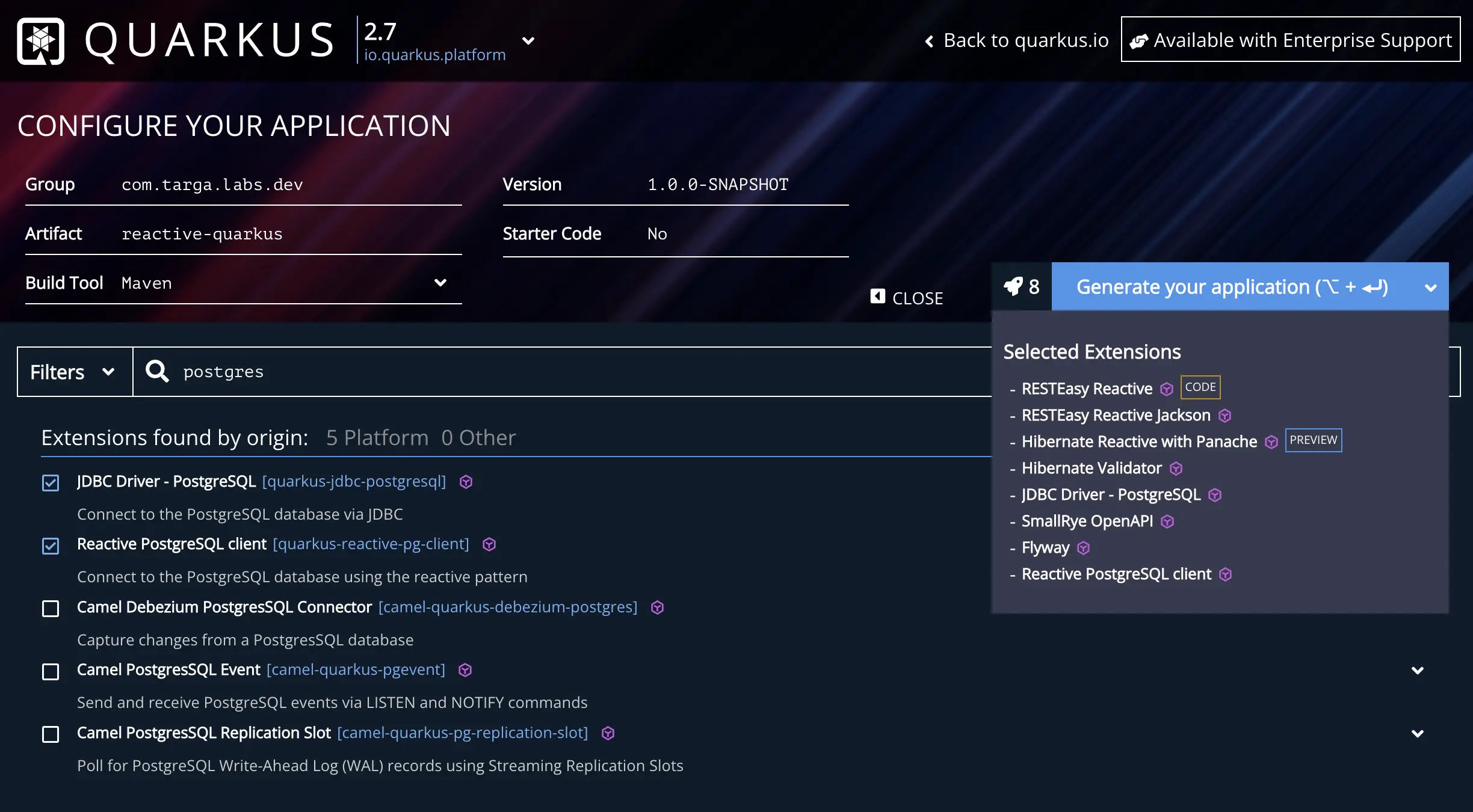
We will generate our project using the code.quarkus.io. Our application will need 8 extensions from the portal:
- RESTEasy Reactive
- RESTEasy Reactive Jackson
- Hibernate Reactive with Panache
- Hibernate Validator
- Reactive PostgreSQL client
- JDBC Driver - PostgreSQL
- Flyway
- SmallRye OpenAPI
Other than these dependencies, we will need some more:
- Lombok for simplifying the code and avoiding all boilerplate stuff like getters/setter, constructors, etc.
- Mapstruct is used to implement a simplified mapping mechanism between JPA entities and DTOs.
- Testcontainers is used to provide lightweight database instances for JUnit Tests.
We will need manually to the pom.xml:
| |
We will need also Test scope dependencies:
| |
In this tutorial, we will use a great feature available in Quarkus called DevServices, which helps you to provision sevices (like DB, Keycloak, Cache Engines, Kafka, etc.) for Dev and Test purposes.
Based on the Quarkus Guides:
Quarkus supports the automatic provisioning of unconfigured services in development and test mode. We refer to this capability as Dev Services. From a developer’s perspective this means that if you include an extension and don’t configure it then Quarkus will automatically start the relevant service (usually using Testcontainers behind the scenes) and wire up your application to use this service.
⚠️ ⚠️ You need to have Docker installed in order to enjoy the Quarkus Dev Services capability.
We will start by configuring DevServices in the application.properties :
| |
The line(s):
- 2, 3 and 4 will activate the DevServices capability for the Datasource, and define the container image as
postgres:13and define the container port to5432. - 5 and 6 will define the Database container credentials
- 7 will disable the JDBC access to the database
- 8 will disable the automatic Flyway migration at startup as it’s not correctly working in the reactive mode. There is already an issue Hibernate reactive + Flyway extension causes UnsatisfiedResolutionException · Issue #10716 · quarkusio/quarkus (github.com)
- 10 and 11 will configure the reactive database connection URL and properties
We will be developing a Reactive version of our famous Books CRUD Application. Our Book entity looks like:
| |
We will start by defining the initial Flyway migration script in the resources/db/migration folder:
| |
Then, we need to create a Flyway migration component that will use the DevServices credentials to load this script to our Database:
| |
The FlywayMigrationService will grab the DevService Database credentials and will load all the migration scripts stored in the Flyway directory.
Next, we will create a Reactive Repository to manage our Books in our DB:
| |
ℹ️ The
PanacheRepositoryBaserepresents aRepositoryfor a specific type of entityEntity. Implementing this repository will gain you similar useful methods that are on Spring DataJpaRepositorylike:
- findAll()
- findById()
- persist()
- update()
- delete()
- etc..
Then, we will create the BookService component with an injected BookRepository:
| |
Then, in the Service layer, we will implement the CRUD operations thru the Repository in the Reactive mode.
Implementing the findAll() method
To grab all entities of the Book entity, we will be call the findAll() method of the BookRepository. In the PanacheRepositoryBase interface, the findAll method returns a PanacheQuery<Entity>.
ℹ️ A PanacheQuery is an interface representing an entity query, which abstracts the use of paging, getting the number of results, and operating on
ListorStream. ThePanacheQueryinterface will get its implementation based on the shipped Panache dependency that we have. In our case it will be implemented in thePanacheQueryImplclass from theio.quarkus.hibernate.reactive.panache.runtimepackage from thequarkus-hibernate-reactive-panacheextension.
The list() method from the PanacheQueryImpl class returns a Uni<List<T>>.
But, what is the Uni type ?
A
Uni<T>is a specialized stream that emits only an item or a failure. Typically,Uni<T>are great to represent asynchronous actions such as a remote procedure call, an HTTP request, or an operation producing a single result.
Uni<T>provides many operators that create, transform, and orchestrateUnisequences.– SmallRye Mutiny documentation
In the BookService, we can use the list() method from the PanacheQueryImpl class to grab all the books. The findAll() will look like:
| |
ℹ️ Actually, there is a shortcut to the findAll().list() in the PanacheRepositoryBase interface, but I wanted to take you in a tour to show you how things are already made.
Then, we will create the BookResource to expose the findAll() operation:
| |
We are wrapping the List<Book> inside the Uni<Response>.
Then, if you run the Quarkus application using the mvn quarkus:dev command, then we can test the findAll REST API using the Swagger UI available on http://localhost:8080/q/swagger-ui/:
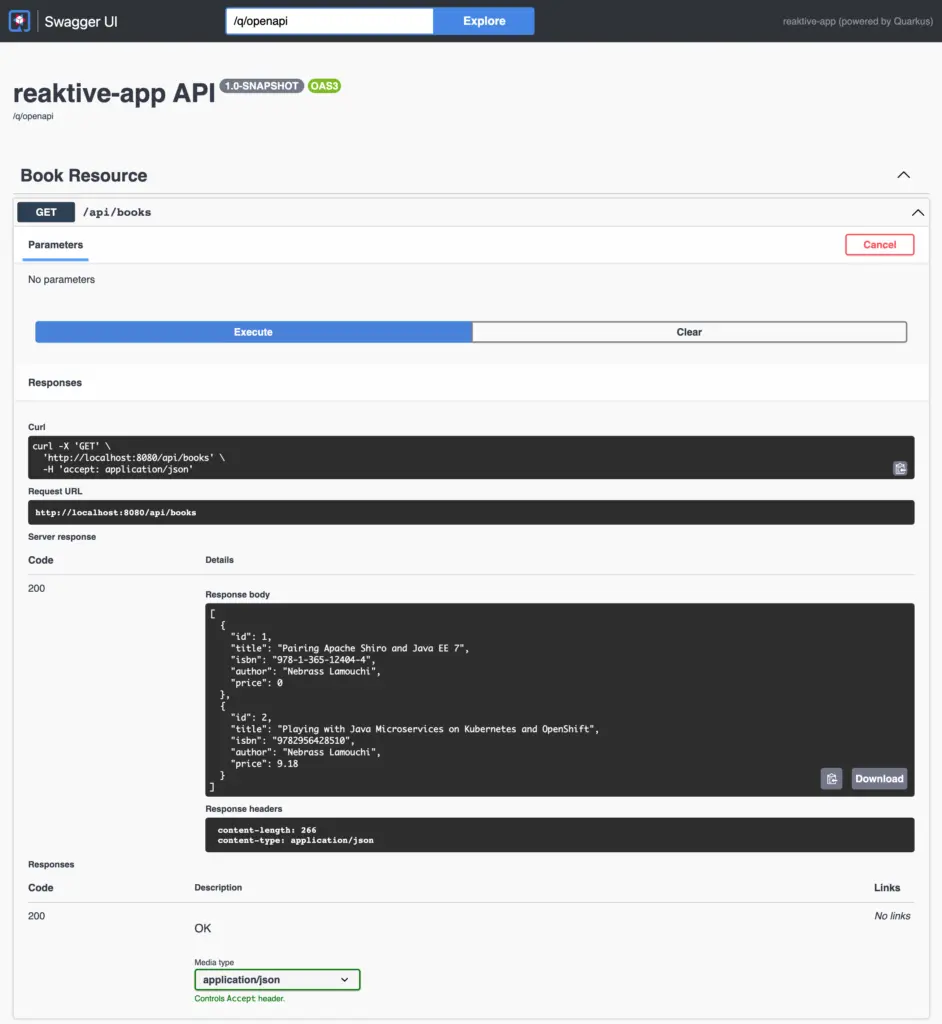 findAll REST API - Swagger UI
findAll REST API - Swagger UI
Implementing the save() method
After implementing the findAll() method, we need to create the one that inserts records in the database 😅
In our REST API, the save() method is called with JSON Payload holding a new book details. These details can be defined as a DTO Model class that I will call BookDTO:
| |
In the BookResource class we need to add a new method that is called using the HTTP Post Verb and that consumes as JSON Payload the BookDTO:
| |
The line(s):
- 1: will delegate the saving task to the
bookService.save()method. - 2: if the
save()succeeds then we will return the created Book entry in the Response body. - 3: if the
save()fails then we will return an HTTP Bad Request (400) in the Response body.
Now, we need to create the save() method in the BookService. This is will be obviously calling the BookRepository save method:
| |
You can notice that the persistAndFlush() method returns a Uni<Book> which we already discovered in the previous part of this tutorial.
Hmm.. I have something to modify in my BookService after introducing the BookDTO class. I wonder:
- Why do I need to return the all the
Bookentity records in myfindAll()method ? Why I dont return instead the entity records wrapped as DTO instances ? Is this will be better or it’s just an overhead ?
The RESPONSE is: THIS IS MUST BE DONE ⚔️🛡⚔️ But why ?
The DTO pattern is highly useful in many cases:
- Returning the plain data directly from the database to the user can be dangerous when the entity records hold sensitive data such as password, payments credentials, adresses, etc. So records mapping to DTOs is a must - as you cannot obfuscate data on the record instance itself 😁
- The DTO offers the ability to provide the data that is needed in different contexts. For example, the
findAll()method in a page that needs only the books titles and prices is not the same as a page that needs the books titles and isbns only. DTOs here will be offering the possibility to create a separate DTO dedicated for each need.
💡 It’s true that in our example none of these needs are present, but I will use the DTO for learning purposes 🥹
My findAll() method with DTOs will look like:
| |
Hhmmmmmmmm.. in the save() method I instanciated a new Book instance and I passed the attributes to the constructor, and here I passed the attributes from the entity record to the instanciated DTO constructor. Ok this is clear, but headache and it’s not beautiful 🤮
One idea, is to create Mapping methods:
| |
Then my findAll() and save() methods will look like:
| |
Ouuuf 😩 This is better, but it will be better if there are any cleaner way.. I know it will be crazy to create 2 x N methods if we will have N different DTO for each entity. The good news is that there is an excellent solution to do this: Java bean mappings utility classes !
Hmm 😒 the name is no so funky ! I know ! But this is what is called. I won’t reinvent the wheel 😁
Implementing the Mapping mechanism
In the Java World, there are many libraries that helps to do dynamic mapping from an entity to its corresponding DTO classes. Since 2016, I was trying many of them like: MapStruct, Dozer, ModelMapper, JMapper, etc. But the best one that suited my needs is MapStruct.
You can read about benchmarking and performance of the different available libraries here @Baeldung: https://www.baeldung.com/java-performance-mapping-frameworks.
To add MapStruct to our application, we start by adding the MapStruct Maven dependency to our pom.xml:
| |
Then, in the Maven POM build section, we need to configure the compiler to take into consideration the MapStruct processor along with the Lombok processor:
| |
Now, we need to create the MapStruct Mapper class that will reference the Entity and the DTO:
| |
This interface defines:
- the generated mapper as an application-scoped CDI bean and can be retrieved via
@Injectannotation. - different methods that maps:
- an entity to a DTO
- a DTO to an entity
- an entities list to a DTOs list
- an update Entity from a DTO definition
Excellent ! Now, we can add the BookMapper reference for injection in the BookService class:
| |
Then we can use the BookMapper in our findAll() and save() methods:
| |
💡 In the
save()method, we used the mapper to create a Book instance from the DTO, and then convert the stored Book record to a DTO instance.
That’s all tale! The MapStruct will do all the magic!
Behind the scenes, the Maven Compiler will use the MapStruct Processor to implement the MapStruct Mapper via the BookMapperImpl.java class, available after compilation, in the /target/generated-sources/annotations/ directory:
| |
Great! I feel very comfortable for delegating the DTO Mapping load to MapStruct 😁 As I always say: “A Good Developer is a Lazy Developer” 😂
Implementing the findById, findByAuthor and deleteById methods
Now, we will continue to implement our CRUD methods - like:
findById(): find a book using a given book ID.findByAuthor(): find books using a given author name.deleteById(): delete a book using a given book ID.
The implementation looks like:
| |
The line:
- 1: defines the Hibernate Query that is used to search by author name with ignore case.
- 2: runs the method into a reactive
Mutiny.Session.Transation.
Then, their REST APIs look like:
| |
That’s all tale ! 😁 We made our first Quarkus Reactive application ! You can now write some integration tests using RestAssured to be sure that all is working as expected 🤩
If you have questions, please feel free to get in touch with me 😎